Making an LLM

Art by tapiokurii
| GitHub Repo 👾 | Scope: ⭐⭐⭐⭐⭐ |
Large language models, or LLMs, are undoubtedly the technology of our time. The fact that you can talk to a piece of software like you would a person boggles my mind. These programs are so incredible that I just had to make one. There is only one slight problem: I don’t have millions of dollars to spend on this project. The creation of a modern chatbot of the quality of ChatGPT, Gemini, or Claude is therefore completely infeasible for any one person. So I set out to hand code an LLM, from the ground up, on a hobby budget. But first I would need to create a plan of attack.
The Plan
I had a series of specifications for my language model. First, because I thought it would sound cool, I wanted a model with at least a billion parameters. For infrastructure, I wanted to train entirely locally using my 32 GB VRAM GPU (an NVIDIA RTX PRO 4500 Blackwell). I also planned for my model to be english-only, and (as an unorthodox choice) to be uncased. The idea was to reduce the computation the model would have to designate to language styling, and focus more on syntax, grammar, and basic world knowledge. In terms of data, I wanted to avoid synthetic data (chatbot-generated) as much as possible, as otherwise I’d just be making a bad distillation. Finally, I decided that because my language model would be very small relative to the frontier, I should call it qt. I also made a ASCII logo for qt, to emphasize its small, simple nature.
1
2
3
4
5
6
7
8
9
10
___ ___
/\ \ /\ \
/88\ \ \8\ \
/8/\8\ \ \8\ \
\8\~\8\__\ /88\ \
\8\/8/ / /8/\8\__\
\88/ / /8/ \/__/
/8/__/ /8/ /
\8\__\ \/__/
\/__/
Architecture
There have been a ton of improvements to GPTs since GPT 2. After reading a series of architecture papers, I finalized the specifics, focusing on simple improvements to the basic MHA decoder-only transformer. This let me pick qt to be a dense GQA ALiBi/NoPE flash attention transformer, using RMSNorm and GELU activations. This architecture would reduce the KV cache for inference, and better extrapolate to longer sequences than seen during training. RMSNorm is standard for activation normalization now, and I choose GELU essentially randomly. To get the model to a billion parameters, I chose the following specifications (closely related to the LLaMa 3 architecture):
1
2
3
4
5
6
7
8
9
10
vocab size: 10,001
parameters: 1.01B
embedding: 20.5M
non-embedding: 879.5M
d_model = 2048
ffw_size = 8196
n_heads = 32
n_heads_kv = 8
n_layers = 22
seq_len = 512
Now that it was decided, I got to training!
Pre Training
The Chinchilla Scaling Laws say that a compute optimal language model with 1 billion parameters should be pretrained on about 20 billion tokens. I sourced ~21.5B tokens from the fineweb-edu dataset.
I preprocessed this text to be only lowercase, removing any characters that were not punctuation, numbers, letters, or white space characters, and substituted the various unicode quote characters with the most common variant, ie.
1
2
3
4
5
6
punctuation_map = {
0x201C: 0x22, # LEFT DOUBLE QUOTATION MARK -> "
0x201D: 0x22, # RIGHT DOUBLE QUOTATION MARK -> "
0x2018: 0x27, # LEFT SINGLE QUOTATION MARK -> '
0x2019: 0x27, # RIGHT SINGLE QUOTATION MARK -> '
}
I then trained a BPE tokenizer on this data using the HuggingFace tokenizers library. When doing this, I only allocated 10,000 embeddings for my model. This is very small, but I was hoping that this would be enough to focus on the “simplified” language content of my preprocessed training data. If something slipped though, I did add the [UNK] token to the vocabulary, though this should be exceedingly rare in my dataset.
Before conducting pretraining, I wanted to be very sure it was going to work. I follow a lot of the advice provided in the excellent HuggingFace resource The Smol Training Playbook:The Secrets to Building World-Class LLMs.
I trained using AdamW with BETA_1 = 0.9, BETA_2 = 0.95, WEIGHT_DECAY = 0.1. I used the WSD learning rate schedule with 1000 warmup steps and 2000 cooldown steps. The batch size was 2000 sequences of 512 tokens, or a 1.02M token effective batch size. To fit on my GPU, I accumulated 16 sequences at a time, and accumulated every 125 iterations. I had a bug where I accidentally cast the whole model to bfloat16 instead of doing mixed precision training, which resulted in a failed run I caught after 2 days. Amusingly, the HuggingFace SmolLM team faced a similar issue for their post-traing. After I got that resolved, the training loop ran for ~353 hours, or just under 15 days.

After a very long 15 days, I got the following learning curve, ending with a train loss of ~2.3.
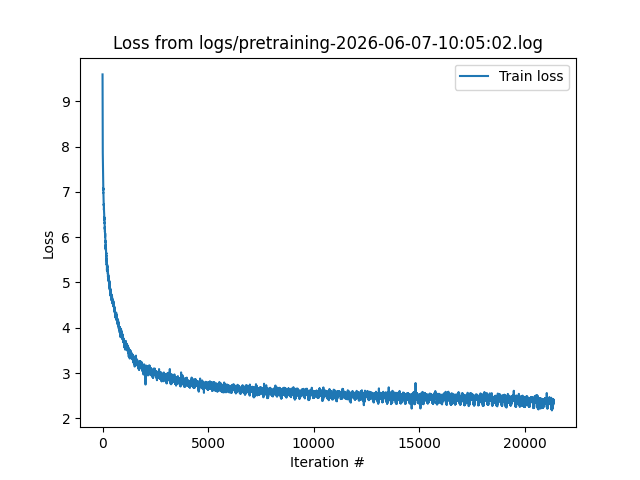
Zooming in on the last 15k iterations…
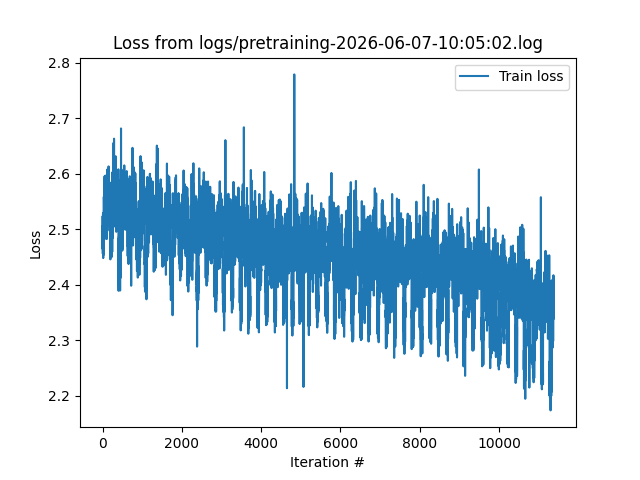
The massive spike is from when I lost power, which ended up flushing the optimizer’s state and hurting performance for a bit before recovering. One can also see how the tail end of WSD leads to performance gains at the very end of pretraining.
I made a quick hacky (greddy) decoder to test out generation of the pretrained model. Since there were no [EOS] tokens in pretraining, I decided to truncate generation at 64 tokens. I was very happy to see the following generation pop out.
1
2
3
4
[BOS] my name is jack hanke. i like to make programs. what is my name?
## generation begins, this line is not included in the prompt
jack▁hanke▁is▁a▁computer▁scientist▁at▁the▁university▁of▁california,▁berkeley.▁he▁is▁the▁author▁of▁the▁book▁"the▁art▁of▁computer▁programming".▁he▁is▁also▁the▁author▁of▁the▁book▁"the▁art▁of▁computer▁programming".
jack▁hanke▁is▁a▁computer▁scientist▁at▁the▁university
It looks like qt has mixed me up for Donald Knuth. Trust me, I’m not that guy pal.
Anyways, it was time for post training!
Post Training
Avoiding large amounts of synthetic data was easy for pretraining, but not so much for post training. There are many “GPT Conversations” datasets available that I wanted to avoid. I considered other dataset options from the paper Instruction Tuning for Large Language Models: A Survey, but decided against it. I eventually settled on the following.
- For dialogue tuning, I use:
- For instruction tuning, I use:
Finally, to create qt’s personality, I wrote up a small collection of sample conversations with the personality I was hoping for. I only wrote 10 conversations, so unfortunately this turned out not to be enough to instill any meaningful change in qt’s responses.
This training only took about an hour on my machine, and I was ready to make some generations!
Example Generations
Here is an example of a conversation where I ask qt about pizza.
Visualization
Here is an example of animating qt’s internal thoughts for generating the next word. I take the 2-dimensional PCA of qt’s 2048-dimensional token embeddings, and connect the individual points for each token with a line to indicate sentence order. When sending the tokens to qt, I change the points to the color red, and take the same PCA transform of the internal activations for each half layer (attention and feed forward). I then show the final token turns out to be closest to the answer, “breakfast”.

If I were to do it again…
Perefection is the enemy of good. But I did learn some things. If I were to do it again, I would:
- Use the 400B ClimbMix dataset for more varied, high quality data.
- Try token superposition pretraining to drasically speed up pretraining.
- Rent a GPU cluster (I’m not waiting 15 days again).
- Make the vocab size slightly larger, to make a squatter 1B model (and therefore faster inference).
- Track bit-per-byte as opposed to cross entropy for pretraining for a more standard performance metric.
- Implement beam search.
- Possibly add emojis to vocab, just for fun 🫠.
- Scaling! More parameters! More layers! More data!
Thank you for reading!